分布式队列的实现和分布式锁的思想很类似,在指定的节点下,写入有序的子节点,出队时节点序号最小的先出队。代码实现如下:
1 |
|
分布式队列的实现和分布式锁的思想很类似,在指定的节点下,写入有序的子节点,出队时节点序号最小的先出队。代码实现如下:
1 |
|
目前Java运行环境中多数都是集群环境,多台主机并行计算,导致在代码中很难进行并发控制,有开发人员自行实现分布式锁,开发工作量大,代码稳定性难以保证,ZooKeeper框架的出现,让开发人员可以使用zk中成熟的分布式锁服务,减轻了开发人员对分布式任务并发控制负担,可以专注业务逻辑实现。
zk中分布式锁的思想是,创建一个锁节点/locknode/guid-lock,集群中每台服务器都在该节点下写入有序的子节点,节点列表中第一个节点对应的服务器被认为是拿到分布式锁,可以进行计算任务,计算任务结束后,删除该服务器对应的节点,下一个服务器写入的节点排到了第一位,可以进行计算任务,如此往复,每台机器写入的节点排在列表中第一位的时候,就被认为是拿到分布式锁。
1 | package org.zk.distributed.lock; |
在使用zk实现分布式锁服务时,需要注意一点,如果服务器监听锁节点下所有子节点,那么zk集群在负责发起watcher通知时,势必给zk集群服务带来压力,而客户端关注了与自己无关的节点变化情况,也浪费了客户端服务器资源,这种情况叫做羊群效应。羊群效应的解决方案是,每个客户端服务器只关注比自己小的那个节点的变化情况即可,如果比自己小的节点被删除,那么就说明当前服务器拿到分布式锁。
目前Java web应用中大规模使用分布式系统和集群,集群中存在多台服务器对外提供服务,那么就存在一个问题,如何确定一个请求应该分发到哪台服务器上呢,这就需要获取当前服务器CPU、内存、网络、文件句柄的使用情况,合理分发请求,以使集群中所有服务器达到负载均衡的效果。
获取CPU利用率
代码实现
负载均衡
服务器端负载均衡分为算法包括:轮循算法(Round Robin)、哈希算法(HASH)、响应速度算法(Response Time)、加权法(Weighted )等。网上有文章提到“最少连接算法(Least Connection)”也是负载均衡算法的一种,当然,这样说是需要有前提条件的,就是当服务器性能良好,可以及时处理所有请求的时候,最少连接算法才能达到负载均衡的目的,否则最少连接的服务器可能正在处理比较耗时的操作,继续将请求分发到该服务器可能导致该服务器load值升高,性能下降。参见https://devcentral.f5.com/articles/back-to-basics-least-connections-is-not-least-loaded 。之后我会写关于负载均衡各类算法的博客。
ZK实现负载均衡使用zk做负载均衡,需要在zk上指定path下注册提供服务的集群中每个节点的ip地址,消费者需要在该path上注册watcher,当服务提供者集群中增删几点时,zk会发起watcher通知,所有消费者都会收到该watcher回调,此时,消费者可以及时知晓服务提供者集群中节点状况,在可用服务器列表中进行负载均衡计算。
发布/订阅点击这里查看发布/订阅讲解
1 | <properties> |
命名服务点击这里查看命名空间讲解
1 | <properties> |
ZK客户端类
刚刚开始使用idea,运行junit test类的时候输出到控制台的中文都是乱码
———————————华丽的分割线—————————————
解决方案:要运行的文件窗口右键->File Encoding>弹出框中选择UTF-8
总结:网上有的文章叙述问题解决方案的时候铺垫会比较多,花时间浏览到最后还不一定解决问题,看些比较短小的文章受些启发,再自己探索效果更好。
Zookeeper简称ZK,是高性能、高可用的分布式协调框架,采用了自定义的ZAB(Zookeeper Atomic Broadcast)事务一致性协议,在高并发分布式系统环境中保证事务一致性。ZK采用类似Linux操作系统文件目录结构管理节点,节点数据常驻内存,避免磁盘I/O影响性能,并提供对用户透明的持久化功能保证数据安全。ZK适用于小量数据、高性能、高并发的应用场景。
ZooKeeper为用户提供以下服务:
命名服务命名服务(Naming Service)提供了一种为对象命名的机制,可以定位任何通过网络可以访问的机器上的对象,使得用户可以在无需知道对象位置的情况下获取和使用对象。服务提供方在ZK上创建临时Node(全局唯一),服务消费方通过读取ZK上的临时Node节点获取到服务提供方信息,进而调用服务提供者。通过ZK的命名服务,可以达到服务提供者动态增加或减少服务提供者服务器数量。典型示例:阿里的Dubbo框架,即采用ZK作为注册中心。[代码示例]
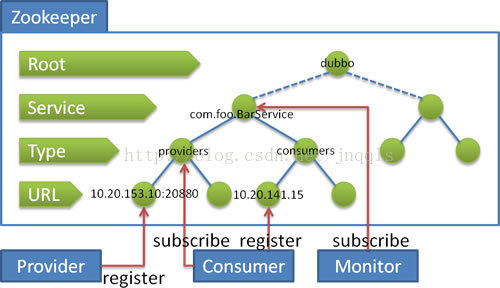
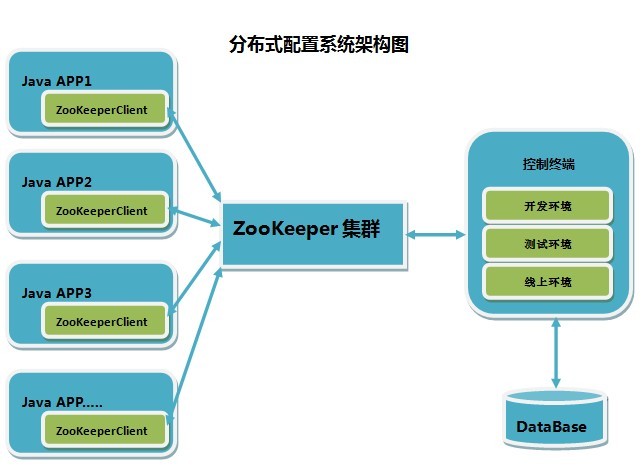
发布订阅服务发布订阅模型,即配置中心,可将应用可配置项发布到ZK上,供订阅者动态获取配置,同一集群使用同一套配置,实现配置集中、动态管理,避免修改配置后重启应用服务。
负载均衡由于分布式系统的使用越来越多,为了使同一集群内的多台服务器负载更均衡,就需要一个能够根据服务器负载情况进行请求分发的框架,ZK正是这种可以根据服务提供者列表进行请求分发的框架,可以动态的注册和发现服务,使服务更透明,实现软负载均衡和故障恢复。